osmc:Metodologia
Documentação integrante do projeto AFA.codes |
| Países: BR, CO, EC, UY. |
| Afa vs Plus, DNGS, ... |
Descrição da metodologia e algoritmos do sistema AFA.codes. Segue em parte um padrão, em parte as decisões soberanas do país.
O sistema AFAcodes implementou a metodologia sugerida pelo padrão DNGS, portanto muito parecida com a do padrão ISO DGGS, ambas iniciam por uma grade grosseira, particionando uma superfície com grandes células de igual-área.
A diferença da metodologia DNGS para a DGGS é que a superfície DNGS é um território nacional, ao invés do globo inteiro. O padrão DNGS é também mais restritivo, impõe projeção válida (oficial nacional), geocódigos válidos, tamanhos e formatos de célula válidos (quadriláteros em potências de 2) e um limite ao número de células iniciais (até 16).
Projeção e cobertura nacionais
Começa-se com o mapa dos limites territoriais na projeção igual-área adotada oficialmente pelo país, designada projeção igual-área nacional. Os limites podem abranger a Zona econômica exclusiva e arquipélagos, conforme decisão soberana do país.


Conforme a convenção IEC de prefixos binários, múltiplos de 1024 metros são abreviados como Kim (kilobinary meter).
Sobre o polígono dos limites territoriais é encaixada uma grade de potência de 2 (tabela ao lado), onde será desenhado um mosaico de no máximo 16 quadrados. O encaixe é obtido por um algoritmo de varredura, testa-se com grades maiores e menores, sobre a BBOX dos polígonos territoriais.
No caso da Colômbia o melhor encaixa foi conseguido com quadrados de 219 m de lado, ou seja, 219 m =524,29 km = 512×1024 m = 512 Kim.
Abaixo, em roxo, com ij as coordenadas i horizontal e j vertical, o conjunto dos quadrados que cobrem o território, apelidado de "cobertura nacional".

Escolha oficial da origem

Conforme previsto na metodologia DNGS para escolha das coordenadas de referência, um ajuste fino da posição da cobertura nacional é necessário para se estabelecer em definitivo o sistema de coordenadas e, consequentemente, os identificadores de célula.
Apesar de ser uma escolha objetiva, baseada no simples encaixe nos limites oficiais, a escolha desses limites requer decisões suberanas, tais como escolha do buffer de segurança, e decisões sobre uso ou não da zona econômica.
No caso da colômbia a origem é o ponto XY (3678500,1494288) na projeção de SRID=9377.
PS: as outras alternativas (ex. sem parte insular nem zona econômica), descartadas, foram documentadas.
Decisões sobre ajuste e desmembramento

O algoritmo de escolha das células L0 é relativamente simples, resulta da interseção do polígono com a grade: se o número de células exceder a 16, será utilizada uma grade de nível mais grosseiro.
Por ser uma decisão definitiva e com grande impacto na posterior usabilidade da grade, é uma decisão delicada, requer "ajuste humano", e portanto decisões adicionais. Principais exemplos de causa e ajuste: erros implícitos nas delimitações territoriais, importância das delimitações (divisor oceânico vs divisor territorial), decisões por reserva (maior em territórios disputados) e descontinuidades, tais como as ilhas do Havaí no polígono territorial dos EUA, que requerem inclusive uma projeção diferente.
Uma das soluções técnicas para garantir a cobertura nacional em 16 células L0 é o desmembramento, ilustrado para o caso do Brasil. O algoritmo de cobertura requer mínimo de ~30% de taxa de ocupação territorial sobre a célula de cobertura. As células com "grandes vazios" são candidatas ao desmembramento para que seus geocódigos possam ser reutilizados em porções desconexas, tipicamente as insulares (ilustração).
Indexação L0
Em seguida os 16 quadrados recebem indexadores (rótulos) sequenciais no lugar de coordenadas ij.

A sequência de indexação é arbitrária, poderia ser de cima para baixo da esquerda para a direita. Todavia, a formação da grade, conforme veremos a seguir, exige a escolha de uma curva de preenchimento (Curva-Z no caso foi a escolha soberana da Colômbia).
Os cálculos de vizinhança na curva de preenchimento são complexos, quanto maior a quantidade de células L0 que preservarem a distribuição de vizinhança original, mais simples o algoritmo de cálculo de vizinhança. Simplificar ou não o algoritmo (otimizar) é também uma decisão soberana.

Na Colômbia a decisão foi por otimizar, ou seja, seguir-se, dentro do possível, a curva de preenchimento em L0. Na ilustração ao lado a cobertura continental em amarelo, e os índices fora de ordem em roxo. O indexador, para sua representação humana, usando a representação hexadecimal (base 16), que vai de "0" a "9" e "a" a "f".
A partir de então, conforme veremos, é adotado como oficial (notação científica para o Censo e outras aplicações) o rótulo hexadecimal de células da grade oficial, tendo como primeiro dígito os rótulos do mapa acima, do nível L0.
Formação da grade científica nacional
A partir dos quadrados da cobertura nacional será formada a grade, de modo que são apelidados de "células da grade nivel zero" (abreviadamente "células L0"). As células são todas iguais, com mesma área e formato.
Em seguida cada célula L0 é subdividia sucessivamente em 4:

Tomando como exemplo a Colômbia temos:
- A primeira subdivisão das células L0 resulta em células da grade nível L1, cada uma das 4 células com lado h1 = h0/2 ≈ 256 km.
- Em seguida a subdivisão das 4 células L1 resulta em células da grade nível L2, cada uma das 4 células com lado h2 = h1/2 = h0/4 ≈ 128 km. A cada célula L0 correspondem portanto 4×4=16 células L2.
- Em seguida a subdivisão das 16 células L2 resulta em células da grade nível L3...
- ... Até chegar nas células da grade nível L19, com 1 m de lado.
A grade nacional L0 tem 16 células ao todo cobrindo o território nacional, de modo que são ao todo 16×4=64 células L1, 16×16=256 células L2, e assim por diante, até que no nível L19 as células possuirão 1 metro de lado, e serão bilhões de células cobrindo o território nacional.
O indexador desse conjunto hierárquico de grades não é um número mas um código natural, de modo que a rotulação numérica hexadecimal tradicional foi extendida para que todos os códigos possam ser devidamente representados, além dos níveis pares:

Há ainda a possibilidade de criar "grades degeneradas", geometricamente unindo células vizinhas da sequência de indexação. Essa união de vizinhas resulta em grades retangulares ao invés de quadradas, e seu nível hierárquico é contabilizado como "nível meio" (L½, L1½, L2½, ...).
O efeito prático disso é o mesmo que subdividir em 2 sucessivamente, de modo que todos os códigos binários com 1 a 19×2=38 dígitos binários (bits) podem ser representados por células em 38 grades distintas, formando um sistema hierárquico de grades. Grades L0, L½, L1, L1½, L2, L2½, ..., L18½, L19.
As células dessas grades serão sempre identificadas por um código expresso na "notação científica", a base16h (que é a hexadecimal extendida para toda a hierarquia).
Geocódigo logístico
Um subconjunto da grades científicas é utilizado nas aplicações logísticas, tendo em vista que o geocódigo hexadecimal é muito longo para o ser humano memorizar.
Para o geocódigo logístico, é necessário ter um código mais fácil de recordar, composto de:
- um prefixo, muito fácil de lembrar porque é o próprio município descrito em formato abreviado. Por exemplo
CO-Tunjana Colômbia ouBR-SP-SJC(São Jose dos Campos) no Brasil;
- um sufixo de 4 a 6 caracteres representando células da grade, para se localizar a porta de casa. Em países maiores o sufixo pode (conforme decisão soberana) ser expresso na Base32.
Por exemplo "GGQT" sufixo deCO-Tunja~GGQTno meio urbano de Tunja; "2YNHP" sufixo deBR-SP-SJC~2YNHPno meio rural de São José.- o primeiro dígito desse sufixo de grade é, a rigor, ainda parte do nome. O dígito surge com a detecção do território municipal. Por exemplo
CO-Tunja~G, conforme veremos, tem o primeiro dígito "G" definido junto com o nome.
- o primeiro dígito desse sufixo de grade é, a rigor, ainda parte do nome. O dígito surge com a detecção do território municipal. Por exemplo
Para chegar no código logístico, o prefixo BR-SP-SJC aponta para a cobertura do município, que consiste num conjunto indexado de até 30 células que cobrem o município, sendo que cada uma é associada a um índice, escolhido num alfabeto de 32 caracteres, descrito nas variantes da Base32.
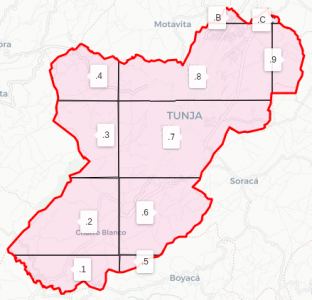
Cobertura-base de Tunja, composta de 11 células, já rotuladas pelo indexador base32.
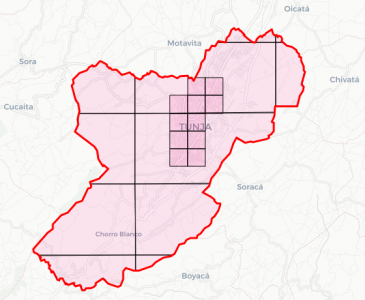
Coberturas base e overlay sobre Tunja (CO-15001).
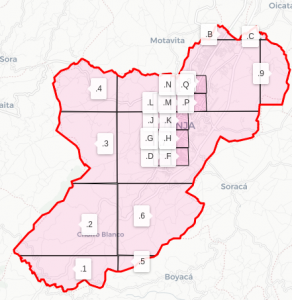
Coberturas base e overlay com respectivos rótulos.
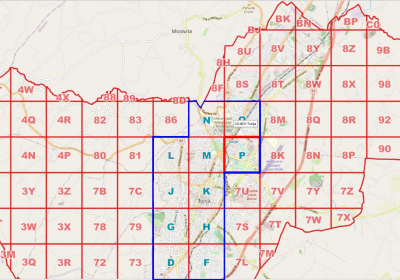
Detalhe da grade de Tunja com geocódigo logístico de 2 dígitos na área rural e 1 dígito na urbana, onde foram definidas células de overlay (contorno azul).




{kind=link}
Estas 30 células cobrem o município de maneira otimizada. São as células da cobertura do município. Só definimos até 30 células para ter 2 de reserva, caso tenha alguma mudança futura no polígono do município.
O digito correspondente a cada célula de cobertura municipal vai ser o primeiro digito do sufixo do código logístico.
Podemos imaginar que cada uma das células da cobertura é dividida em 32, sucessivamente, até chegar a um nível de 1 m. Cada vez que a célula é dividida em 32, o sufixo do código é acrescido de um digito. Na prática, a grade da base32 reusa um subconjunto da grade científica (base2).

No momento de definir a cobertura do município, é possível privilegiar a cobertura da área urbana para garantir que o código seja mais curto nestas áreas, ou que a zona apontada seja menor com o mesmo número de caracteres. Podemos considerar como padrão ter sufixos de 6 dígitos, sendo que na área urbana, estes 6 dígitos apontam para células de 6m e na área rural, apontam para áreas de 32m.
As coberturas todas, de todos os municípios, não é uma caixa preta como a definição dos bairros. O padrão DNGS exige que as coberturas municipais sejam dados abertos. No caso dos AFAcodes da Colômbia, que implementam DNGS, os dados das coberturas municipais estão em https://git.afa.codes/CO_new/blob/main/data/coverage.csv
Seletor de jurisdição

A metodologia descrita foi inicialmente adotada para o Brasil, mas em seguida outros países solicitaram adotar ou testar o padrão DNGS. Uma metodologia de seleção foi implantada, para se distinguir e selecionar a grade nacional correta a cada ponto do globo — e seu complemento, a ausência de grade DNGS no restante do globo.
Ela é descrita no padrão DNGS como algoritmo seletor de jurisdição, e adotada apenas nos "raros casos de validação ou onde o usuário ou a interface não sabem em que país estão".
O algoritmo decide, para um ponto Latitude-Longitude, qual jurisdição nacional usar. Ao lado foi ilustrada a decomposição do "globo DNGS" quando analisando apenas Brasil e Colômbia. A verificação de BBOX tem alta performance. O algoritmo consumirá um pouco mais de CPU apenas quando for BBOX de fronteira, onde vai disparar a verificação do polígono local de fronteira.
Ver também
- Detalhamento técnico da metodologia em osmc:Metodologia/Algoritmo SQL
- Convenções AFAcodes:
- Código Natural:
- Generalized Geohash/pt